
티스토리 뷰
반응형
[Java의 정석 - http://www.yes24.com/Product/Goods/24259565]
1. 람다식(Lambda expression)
1.1 람다식이란?
- 람다식(Lambda expression)
- 메서드를 하나의 '식(expression)'으로 표현한 것
- 함수를 간략하면서도 명확한 식으로 표현할 수 있게 해줌
- 익명함수(anonymous function)이라고도 함
- 메스드의 매개변수로 전달되어지는 것이 가능하고 메서드의 결과로 반환될 수도 있음
1.2 람다식 작성하기
- 메서드에서 이름과 반환타입을 제거하고 매개변수 선언부와 몸통{} 사이에 '->'를 추가한다
| 반환타입 메서드이름 (매개변수 선언) { 문장들 } ⬇︎ 문장들 } |
- return 문 대신 '식(expression)'으로 대신할 수 있다
- 식의 연산결과가 자동적으로 반환값이 됨
- 이때는 '문장(statement)'이 아닌 '식'이므로 끝에 ';'를 붙이지 않는다
- 매개변수의 타입은 추론 가능한 경우 생략할 수 있다
- 대부분의 경우에 생략 가능함
- 매개변수가 하나뿐인 경우에는 괄호()를 생략할 수 있음
- 매개변수의 타입이 있으면 괄호()를 생략할 수 없음
- 괄호{} 안의 문장이 하나일 때는 괄호{}를 생략할 수 있음
- 이 때 문장의 끝에 ';'를 붙이지 않아야 한다
- 괄호{} 안의 문장이 return 문인 경우 괄호{}를 생략할 수 없다
1.3 함수형 인터페이스(Functional Interface)
- 람다식은 익명 클래스의 객체와 동등하다
- 함수형 인터페이스(functional interface)
- 하나의 메서드가 선언된 인터페이스를 정의해서 람다식을 다룰 수 있다
- 인터페이스를 통해 람다식을 다루기로 결정되었으며 람다식을 다루기 위한 인터페이스를 함수형 인터페이스라고 부른다
- 인터페이스를 구현한 익명 객체를 람다식으로 대체가 가능한 이유는 람다식도 실제로는 익명 객체이고
인터페이스를 구현한 익명 객체의 메서드와 람다식의 매개변수의 타입과 개수 그리고 반환값이 일치하기 때문이다 - 함수형 인터페이스에는 오직 하나의 추상 메서드만 정의되어 있어야 한다
- 그래야 람다식과 인터페이스의 메서드가 1:1로 연결될 수 있다
@FunctionalInterface
interface MyFunction {
void myMethod();
}
void aMethd(MyFunction f) {
f.myMethod();
}
// 람다식을 매개변수로 지정
aMethod(() -> System.out.println("myMethod()"));
// 람다식을 반환값으로
MyFunction myMethod() {
MyFunctionf = () -> {};
return f; // 이 줄과 윗줄을 하나로 줄이면. return () -> {};
}- 함수형 인터페이스 타입의 매개변수와 반환타입
- 람다식을 참조변수로 다룰 수 있다는 것은 메서드를 통해 람다식을 주고받을 수 있다는 것
- 즉 변수처럼 메서드를 주고받는 것이 가능하다
- 람다식을 참조변수로 다룰 수 있다는 것은 메서드를 통해 람다식을 주고받을 수 있다는 것
- 람다식의 타입과 형변환
- 함수형 인터페이스로 람다식을 참조할 수 있는 것일 뿐 람다식의 타입이 함수형 인터페이스의 타입과 일치하는 것은 아니다
- 람다식은 익명 객체과 익명 객체는 타입이 없다(정확히는 컴파일러가 임의로 지정하기 때문에 알 수가 없다)
- 대입 연산자의 양변의 타입을 일치시키기위해 형변환이 필요하다
- 람다식은 오직 함수형 인터페이스로만 형변환이 가능하다
MyFunction f = (MyFunction) (()->{}); // ㄴ 양변의 타입이 다르므로 형변환 필요(생략 가능) Object obj = (Object) (()->{}); // ㄴ 에러. 함수형 인터페이스로만 형변환 가능
- 람다식은 오직 함수형 인터페이스로만 형변환이 가능하다
- 일반적인 익명객체라면 객체의 타입이 '외부클래스이름$번호'와 같은 형식으로 타입이 결정되었을텐데
람다식의 타입은 '외부클래스이름$$Lambda$번호'와 같은 형식으로 되어있다
- 외부 변수를 참조하는 람다식
@FunctionalInterface interface MyFunction { void myMethod(); } class Outer { int val = 10; // Outer.this.val class Inner { int val = 20; // this.val void method(int i) { // void method(final int i) { int val = 30; // final int val = 30; // i = 10; // 에러. 상수의 값을 변경할 수 없음. MyFunction f = () -> { System.out.println("i : " + i); System.out.println("val : " + val); System.out.println("this.val : " + ++this.val); System.out.println("Outer.this.val : " + ++Outer.this.val); }; f.myMethod(); } } // Inner 클래스의 끝 } // Outer 클래스의 끝 class LambdaEx3 { public static void main(String args[]) { Outer outer = new Outer(); Outer.Inner inner = outer.new Inner(); inner.method(100); // 출력 결과 // i : 100 // val : 30 // this.val : 21 // Outer.this.val : 11 } }
- 람다식 내에서 참조하는 지역변수는 final이 붙지 않았어도 상수로 간주된다
- 람다식 내에서 지역변수 i와 val을 참조하고 있으므로 람다식 내에서나 다른 어느 곳에서도 이 변수들의 값을 변경하는 일은 허용되지 않는다
- Inner 클래스와 Outer 클래스의 인스턴스 변수인 this.val과 Outer.this.val은 상수로 간주되지 않으므로 값을 변경해도 된다
- 외부 지역변수와 같은 이름의 람다식 매개변수는 허용되지 않는다
- 람다식 내에서 참조하는 지역변수는 final이 붙지 않았어도 상수로 간주된다
1.4 java.util.function 패키지
- java.util.function 패키지에 일반적으로 자주 쓰이는 형식의 메서드를 함수형 인터페이스로 미리 정의해 놓았다
- 함수형 메서드 이름 통일 + 재사용성, 유지보수 측면에서 좋음
| 함수형 인터페이스 | 메서드 | 설명 |
| java.lang.Runnable |  |
매개변수도 없고, 반환값도 없음 |
| Supplier<T> | 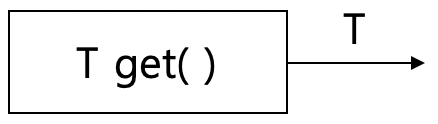 |
매개변수는 없고, 반환값만 있음 |
| Consumer<T> |  |
Supplier와는 반대로 매개변수만 있고 반환값이 없음 |
| Function<T, R> |  |
일반적인 함수 하나의 매개변수를 받아서 결과를 반환 |
| Predicate<T> |  |
조건식을 표현하는데 사용됨 매개변수는 하나, 반환 타입은 boolean |
- 매개변수가 두 개인 함수형 인터페이스
- 접수가 'Bi'가 붙음
| 함수형 인터페이스 | 메서드 | 설명 |
| BiConsumer<T, U> |  |
두개의 매개변수만 있고 반환값이 없음 |
| BiPredicate<T, U> |  |
조건식을 표현하는데 사용됨 매개변수는 둘, 반환값은 boolean |
| BiFunction<T, U, R> |  |
두 개의 매개변수를 받아서 하나의결과를 반환 |
- UnaryOperator와 BinaryOperator
- UnaryOperator<T>
- Function의 자손
- 매개변수와 결과의 타입이 같음
- BinaryOperator<T, T>
- Function의 자손
- 매개변수와 결과의 타입이 같음
- UnaryOperator<T>
- 컬렉션 프레임웍과 함수형 인터페이스
- 다수의 디폴트 인터페이스들이 추가됨
- 기본형을 사용하는 함수형 인터페이스
- 기본형 대신 래퍼(wrapper)클래스를 사용하는 것은 비효율적이기 때문에 효율적으로 처리할 수 있도록 기본형을 사용하는 함수형 인터페이스들이 제공됨
- DoubleToIntFunction : AToBFunction은 입력이 A타입, 출력이 B타입
- ToIntFunction<T> : ToBFunction은 입력은 지네릭, 출력은 B타입
- IntFunction<R> : AFunction은 입력은 A타입, 출력은 지네릭
- ObjIntConsumer<T> : ObjAFunction은 입력이 T, A타입이고 출력은 없음
1.5 Function의 합성과 Predicate의 결합
| Function default <V> Function<T, V> andTen(Function<? super R, ? extends V> after) default <V> Function<V, R> compose(Function<? super V, ? extends T> before) static <V> Function<T, T> indentity() Predicate default Predicate<T> and(Predicate<? super T> other) default Predicate<T> or(Predicate<? super T> other) default Predicate<T> negate() static <T> Predicate<T> isEqual(Object targetRef) |
- Function의 합성
- f.andThen(g)는 함수 f 적용 후 함수 g 적용
- f.compose(g)는 함수 g 적용 후 함수 f 적용
- indentity는 항등 함수가 필요할 때 사용(x -> x)
- Predicate의 결합
- 여러 Predicate를 and(), or, negate()로 연결해서 하나의 새로운 Predicate로 결합할 수 있음
- isEqual()은 두 대상을 비교하는 Predicate를 만들 때 사용
1.6 메서드 참조
- 람다식이 하나의 메서드만 호출하는 경우 '메서드 참조(method reference)'라는 방법으로 람다식을 간략하게 할 수 있다
- '클래스이름::메서드이름' 또는 '참조변수::메서드이름'으로 바꿀 수 있다
- 메서드 참조는 람다식을 마치 static 변수처럼 다룰 수 있게 해준다
- 이미 생성된 객체의 메서드를 람다식에서 사용한 경우에는 클래스 이름 대신 그 객체의 참조변수를 적어줘야 한다
- 예시
| 종류 | 람다 | 메서드 참조 |
| static 메서드 참조 | (x) -> ClassName.method(x) | ClassName::method |
| 인스턴스 메서드 참조 | (obj, x) -> obj.method(x) | ClassName::method |
| 특정 객체 인스턴스 메서드 참조 | (x) -> obj.method(x) | obj::method |
2. 스트림(stream)
2. 스트림이란?
- 스트림
- 데이터 소스를 추상화하고 데이터를 다루는데 자주 사용되는 메서드들을 정의해 놓음
- 데이터 소스 추상화 -> 데이터 소스가 무엇이든 같은 방식으로 다룰 수 있고 코드의 재사용성이 높아짐
- 데이터 소스를 추상화하고 데이터를 다루는데 자주 사용되는 메서드들을 정의해 놓음
- 스트림의 특징
- 스트림은 데이터 소스를 변경하지 않는다
- 스트림은 일회용이다
- 스트림은 작업을 내부 반복으로 처리한다
- 내부 반복 : 반복문을 메서드의 내부에 숨길 수 있음
- 스트림의 연산
- 중간 연산 : 연산결과를 스트림으로 반환하기 때문에 중간 연산을 연속해서 연결할 수 있음
- distinct(), filter(), limit(), skip(), peek(), sorted(), map___(), flatMap____()
- 최종 연산 : 스트림의 요소를 소모하면서 연산을 수행하므로 단 한번만 연산이 가능함
- forEach(), count(), max(), min(), allMatch(), anyMatch(), noneMatch(), toArray(), reduce(), collect()
- 중간 연산 : 연산결과를 스트림으로 반환하기 때문에 중간 연산을 연속해서 연결할 수 있음
- 지연된 연산
- 스트림 연산에서 중요한 점은 최종 연산이 수행되기 전까지는 중간 연산이 수행되지 않음
- 중간 연산을 호출하는 것은 단지 어떤 작업이 수행되어야하는지 지정해주는 것일 뿐
- Stream<Integer>와 IntStream
- 데이터 소스의 요소를 기본형으로 다루는 스트림 : IntStream, LongStream, DoubleStream
- 병렬 스트림
- 내부적으로 fork&join 프레임웍을 이용해서 자동적으로 연산을 병렬로 수행함
- parallel()이라는 메서드를 호출해서 병렬로 연산을 수행
- 취소는 sequential()을 호출
2.2 스트림 만들기
- 컬렉션
- stream() : 해당 컬렉션을 소스(source)로 하는 스트림을 반환
- 배열
- Stream.of() 또는 stream()
- 기본형 배열을 소스로 하는 스트림을 생성하는 메서드도 있음
- 특정 범위의 정수
- range(), rangeClosed(0 : 지정된 범위의 연속된 정수를 스트림으로 생성해서 반환
- 임의의 수
- Ramdom 클래스의 인스턴스 메서드 - ints(), longs(), doubles()
- 해당 타입의 난수들로 이루어진 스트림을 반환
- 무한 스트림(infinite stream)을 반환하므로 limit()도 같이 사용해서 스트림의 크기를 제한해 주어야 함
- 매개변수로 크기를 지정해서 유한 스트림을 생성하는 방법도 있음
- 매개변수로 시작값(begin)과 마지막값(end)을 줘서 지정된 범위(begin~end)의 난수를 발생시키는 스트림을 얻을 수도 있음
- Ramdom 클래스의 인스턴스 메서드 - ints(), longs(), doubles()
- 람다식 - iterate(), generate()
- 람다식을 매개변수로 받아서 이 람다식에 의해 계산되는 값들을 요소로하는 무한 스트림을 생성함
- iterate() - seed로 지정된 값부터 시작해서 람다식에 의해 계산된 결과를 다시 seed로 해서 계산을 반복함
- generate() - 람다식으로 계산된 값을 요소로 반환하지만 이전 결과를 이용하지는 않음
- iterate()와 generate()로 생성된 스트림을 기본형 스트림 타입의 참조변수로 다룰 수 없음
- 필요하다면 mapToInt()와 같은 메서드로 변환
- 그 반대는 boxed()로 변환
- 파일
- Stream<Path> Files.list(Path dir)
- 빈 스트림
- Stream.empty() - 빈 스트림을 생성
- 두 스트림의 연결
- concat() - 두 스트림을 하나로 연결할 수 있음, 연결하는 두 스트림의 요소는 같은 타입이어야 함
2.3 스트림의 중간 연산
- 스트림 자르기 - skip(), limit()
- skip() : 처음 n개의 요소를 건너 뜀
- limit() : 스트림의 요소를 n개로 제한함
- 스트림의 요소 걸러내기 - filter(), distinct()
- filter() : 주어진 조건(Predicate)에 맞지 않는 요소를 걸러냄
- 매개변수로 Predicate나 연산결과가 boolean인 람다식을 사용해도 됨
- distinct() : 스트림에서 중복된 요소들을 제거
- filter() : 주어진 조건(Predicate)에 맞지 않는 요소를 걸러냄
- 정렬 - sorted()
- 지정된 Comparator로 스트림을 정렬
- Comparator를 따로 지정하지 않으면 스트림 요소의 기본 정렬 기준으로 정렬
- 스트림의 요소가 Comparator을 구현한 클래스가 아니면 예외 발생
- Comparator의 default 메서드
- reversed()
- tehnComparing()
- Comparator의 static 메서드
- naturalOrder()
- reversedOrder()
- comparing()
- comparingInt()
- comparingLong()
- comparingDouble()
- nullFirst()
- nullLast()
- 변환 - map()
- 스트림의 요소에 저장된 값 중에서 원하는 필드만 뽑아내거나 특정 형태로 변환해야될 때 사용
- 중간 연산, 하나의 스트림에 여러 번 적용할 수 있음
- 조회 - peek()
- 연산과 연산 사이에 올바르게 처리되었는지 확인하고 싶을 때 사용
- forEach()와 달리 스트림의 요소를 소모하지 않음
- mapToInt(), mapToLong(), mapToDouble()
- Steam<T> 타입의 스트림을 기본형 스트림으로 변환할 때 사용
- 기본형 스트림들은 편리한 메소드들을 제공한다(최종연산)
- int sum() : 스트림의 모든 요소의 총합
- OptionalDouble average() : sum()/(double)count()
- OptionalInt max() : 스트림의 요소 중 제일 큰 값
- OptionalInt min() : 스트림의 요소 중 제일 작은 값
- summaryStatics() 메서드로 IntSummaryStatics같은 값을 받아 sum, count, average, min, max 값을 얻는데 활용할 수 있음
- flatMap() - Stream<T[]>를 Stream<T>로 변환
- 스트림의 요소가 배열이거나 map()의 연산 결과가 배열인 경우, 즉 스트림의 타입이 Stream<T[]>인 경우 Stream<T>로 변환할 때 사용
2.4 Optional<T>와 OptionalInt
- Optional<T> : 지네릭 클래스, 'T타입의 객체'를 감싸는 래퍼 클래스
- 모든 타입의 참조변수를 담을 수 있음
- Optional 객체 생성하기
- of() : 매개변수의 값이 null이면 NullPointerException이 발생
- ofNullable() : 참조변수의 값이 null일 가능성이 있을 때
- empty() : 초기화, null로 초기화하는 것보다 empty()로 초기화하는 것이 바람직함
- Optional 객체의 값 가져오기
- get() : 값이 null일 때는 NoSuchElementException이 발생
- orElse() : null일 때를 대비해서 대체할 값을 지정할 수 있음
- orElseGet() : null을 대체할 값을 반환하는 람다식을 지정할 수 있음
- orElseThrow() : null일 때 지정된 예외를 발생시킴
- 메소드들
- filter(), map(), flatMap()을 사용할 수 있음
- isPresent() : Optional 객체의 값이 null이면 false를 아니면 true를 반환한다
- ifPresent(Consumer<T> block) : 값이 있으면 주어진 람다식을 실행하고 없으면 아무 일도 하지 않음
- Stream 클래스에 정의된 메서드 중에서 Optional<T>를 반환하는 것들
- findAny(), findFirst(), max(), min(), reduce()
- OptionalInt, OptionalLong, OptionalDouble
- IntStream과 같은 기본형 스트림에는 Optional도 기본현을 값으로 하는 OptionalInt, OptionalLong, OptionalDouble을 반환함
- 저장된 값이 없는 것과 0이 저장된 것은 isPresnset라는 인스턴스 변수로 구분이 가능함
2.5 스트림의 최종 연산
- forEach()
- peek()와 달리 스트림의 요소를 소모하는 최종연산
- 반환 타입이 void라 스트림의 요소를 출력하는 용도로 많이 사용함
- 조건 검사 - allMatch(), anyMatch(), noneMatch(), findFirst(), findAny()
- 스트림의 요소에 대해 지정된 조건에 모든 요소가 일치하는지, 일부가 일치하는지 아니면 어떤 요소도 일치하지 않는지 확인하는데 사용할 수 있는 메서드들
- 매개변수로 Predicate를 요구하며 연산결과로 boolean을 반환함
- findFirst()는 스트림의 요소 중에서 조건에 일치하는 첫 번째 것을 반환하는데 주로 filter()와 함께 사용
병렬 스트림인 경우에는 findFirst() 대신 findAny()를 사용해야 함
- 통계 - count(), sum(), average(), max(), min()
- 기본형 스트림에 있는 스트림의 요소들에 대한 통계 정보를 얻을 수 있는 메서드들
- 기본형 스트림이 아닌 경우에는 count(), max(), min()만 있음
- 대부분의 경우 이걸 사용하기 보다는 기본형 스트림으로 변환하거나 reduce()와 collect()를 사용해서 통계 정보를 얻음
- 리듀싱 - reduce()
- 스트림의 요소를 줄여나가면서 연산을 수행하고 최종결과를 반환함
- 처음 두 요소를 가지고 연산한 결과를 가지고 그 다음 요소와 연산한다
- 스트림의 요소를 하나씩 소모하다가 스트림의 모든 요소를 소모하게 되면 그 결과를 반환함
- count()와 sum() 등은 내부적으로 모두 reduce()를 이용해서 작성된 것
2.6 collect()
- collect() : 스트림의 요소를 수집하는 최종 연산
- 컬렉터(collector) : 스트림이 요소를 어떻게 수집할 것인지에 대한 방법을 정의한 것
- 컬렉터는 Collector 인터페이스를 구현한 것으로 직접 구현할 수도 있고 미리 작성된 것을 사용할 수도 있음
- Collector 클래스는 미리 작성된 다양한 종류의 컬렉터를 반환하는 static 메서드를 가지고 있음
- 스트림을 컬렉션과 배열로 변환 - toList(), toSet(), toMap(), toCollection(), toArray()
- 통계 - counting(), summingInt(), averagingInt(), maxBy(), minBy()
- 리듀싱 - reducing()
- collect()로 리듀싱 가능
- 문자열 결합 - joining()
- 문자열 스트림의 모든 요소를 하나의 문자열로 연결해서 반환
- 구분자, 접두사, 접미사 지정 가능
- 스트림의 요소가 String이나 StringBuffer처럼 CharSequence의 자손인 경우에만 결합이 가능하므로 스트림의 요소가 문자열이 아닌 경우에는 먼저 map()을 이용해서 스트림의 요소를 문자열로 변환해야 한다
- 그룹화와 분할 - groupingBy(), partitioningBy()
- 그룹화 : 스트림의 요소를 특정 기준으로 그룹화하는 것
- 분할 : 스트림의 요소를 두 가지, 지정된 조건에 일치하는 그룹과 일치하지 않는 그룹으로 분할
2.7 Collector 구현하기
- Collector 인터페이스에서 구현해야 하는 메서드
- supplier() : 작업 결과를 저장할 공간의 제공
- accumulator() : 스트림의 요소를 수집(collect)할 방법을 제공
- combiner() : 두 저장공간을 병합할 방법을 제공(병렬 스트림)
- finisher() : 결과를 최종적으로 변환할 방법을 제공
- characteristics() : 컬렉터가 수행하는 작업의 속성에 대한 정보를 제공하기 위한 것
- Characteristics.CONCURRENT : 병렬로 처리할 수 있는 작업
- Characteristics.UNORDERED : 스트림의 요소의 순서가 유지될 필요가 없는 작업
- Characteristics.IDENTITY_FINISH : finisher()가 항등 함수인 작업
- collect()는 그룹화와 분할, 집계 등에 유용하게 쓰이고 병렬화에 있어서 reduce()보다 collect()가 더 유리함
2.8 스트림의 변환
- 스트림 -> 기본형 스트림
- ____ToInt()
- 기본형 스트림 -> 스트림
- boxed()
- mapToObj()
- 기본형 스트림 -> 기본형 스트림
- asLongStream()
- asDoubleStream()
- 두 개의 스트림 -> 스트림
- concat()
- 스트림의 스트림 -> 스트림
- flatMap()
- flatMapTo____()
- 스트림 -> 병렬 스트림
- parallel()
- 병렬 스트림 -> 스트림
- sequential()
- 스트림 -> 컬렉션
- collect()
- 컬렉션 -> 스트림
- stream()
- 스트림 -> Map
- collect()
- 스트림 -> 배열
- toArray()
반응형
'study > 자바의정석' 카테고리의 다른 글
| Chapter.15 입출력 I/O (0) | 2021.06.13 |
|---|---|
| Chapter12. 지네릭스, 열거형, 애너테이션 (0) | 2021.06.06 |
| Chapter11. 컬렉션 프레임웍(Collections Framework) (0) | 2021.06.02 |
| Chapter09. java.lang 패키지와 유용한 클래스 (0) | 2021.05.22 |
| Chapter08. 예외처리 exception handling (0) | 2021.05.17 |
댓글
반응형
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- back merge
- kotlin
- Spring
- k8s
- 스프링부트
- docker
- java
- ddd
- 쿠버네티스
- QuickTimePlayer
- gradle
- kotlin In Action
- ImagePullBackOff
- cacheable
- linuxkit
- 클린코드
- docker pull limit
- JavaScript
- 도메인주도설계
- IntelliJ
- 코틀린
- 자바
- Kubernetes
- 스프링
- 도커
- docker for mac
- springboot
- gasmask
- clean code
- 자바스크립트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
글 보관함